タイガーブックを読む:LR(0)構文解析は先読みするのか
最新コンパイラ構成技法(原題「Modern Compiler Implementation in ML」、通称「タイガーブック」)の「3.3 LR 構文解析」の節を読んで理解したことをメモする記事です。 シリーズぽい記事タイトルですが、シリーズにする予定は今のところありません。
LR(n) 構文解析
LR(n) の L、R、n はそれぞれ次の意味を表します。
- L: Left-to-right parse(左から右への構文解析)
- R: Rightmost-derivation(最右導出)
- n: n-symbol lookahead(n 記号の先読み)
左から右、というのは、ソースコードを左から右に読んでいくという意味です。 ソースコードは左から右に横書きするので、構文解析も左から右に処理していくのは自然なことですね。
n 記号の先読みとは、今まで読んだトークンに加えて、n 個のトークンを先読みすることで構文解析の動作を決める方法です。 先読みが多いほど複雑な文法を扱えますが、n=1 で割と十分な記述力を持っているため、n > 1 の文法はなかなかお目に掛かりません。
最右導出というのは、最も右側の非終端記号を展開することによって導出することです。
1+2*3$ という式を次の順に導出することを意味しています。
| 手順 | 導出した記号列 | 適用した生成規則 |
|---|---|---|
| 1 | S $ | 初期状態 |
| 2 | E | S→E$ |
| 3 | E + E | E→E+E |
| 4 | E + E * E | E→E*E |
| 5 | E + E * num | E→num |
| 6 | E + num * num | E→num |
| 7 | num + num * num | E→num |
LR 構文解析表
教科書の p.52 に載っている LR 構文解析表を引用します。LR(1) 文法です。

この LR 構文解析表の見方は、左端にあるのが行番号、上端にあるのが先読みトークンです。表の右部は非終端記号に対するアクションが記されています。 LR(1) なので、先読みトークンは 1 文字ずつになっています。
LR 構文解析の節を読んでいるときの私の最大の疑問は、p.53 で出てくる「LR(0) 構文解析器」でした。 先読みが 0、すなわち入力記号列を見ず、スタックの状態だけで動作を決めることができる、というものです。
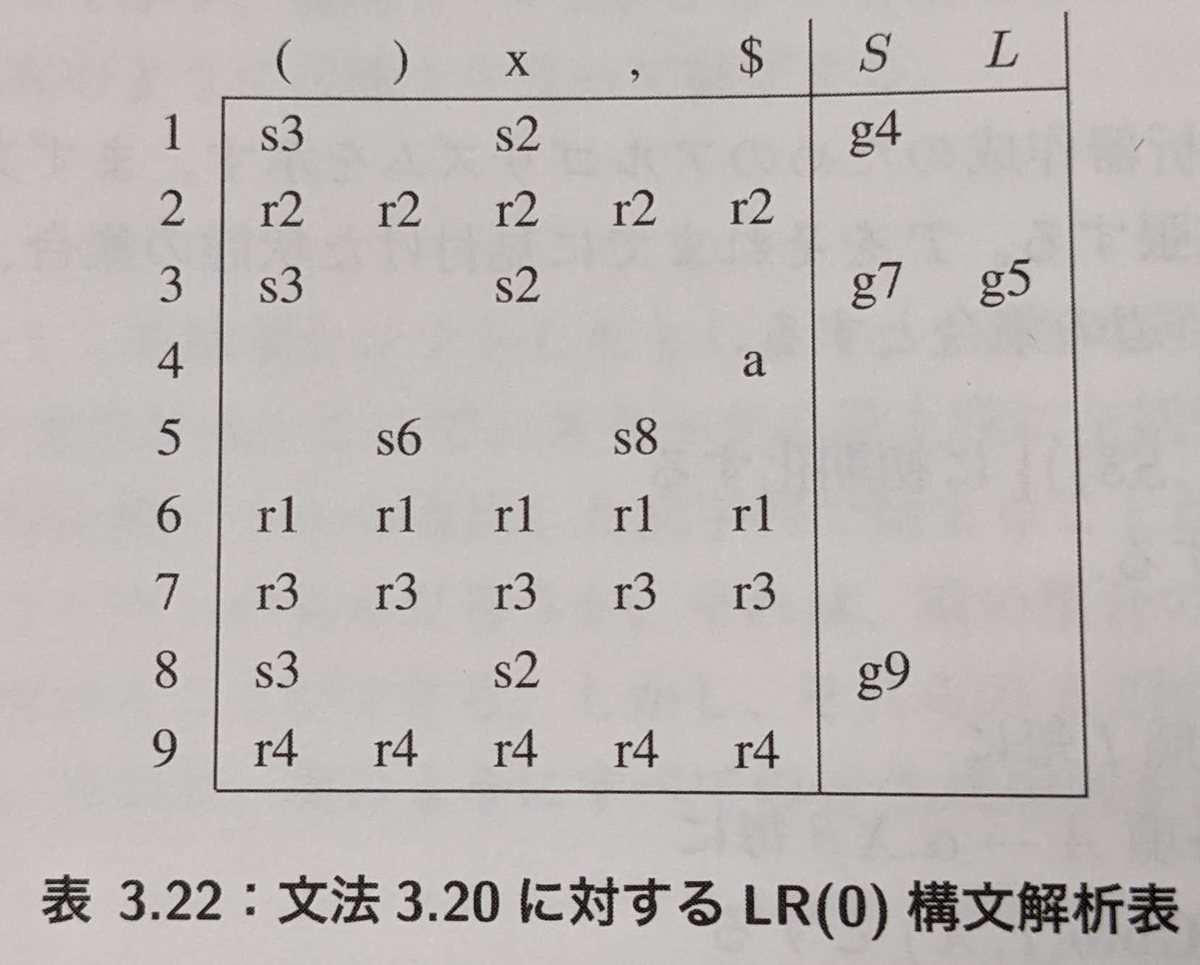
表3.22 は LR(0) 文法に対応した構文解析表のはずなのですが、先読みトークンが書いてあるではありませんか。これはなぜでしょう?
実は、これは先読みトークンではないのです。それを、書き換えた構文解析表を使って説明します。
| Act | ( | ) | x | , | $ | S | L | |
|---|---|---|---|---|---|---|---|---|
| 1 | s | 3 | 2 | g4 | ||||
| 2 | r2 | |||||||
| 3 | s | 3 | 2 | g7 | g5 | |||
| 4 | a | |||||||
| 5 | s | 6 | 8 | |||||
| 6 | r1 | |||||||
| 7 | r3 | |||||||
| 8 | s | 3 | 2 | g9 | ||||
| 9 | r4 |
何を書き換えたかというと、まず Act 列が付け足されたことが大きいです。 そして、各行を次のように書き換えました。
- シフト動作(sN)を含む行:Act 列に「s」を記載し、「先読みトークン」に対応するカラムから「s」を削除
- 還元動作(rN)を含む行:Act 列に「rN」を記載し、「先読みトークン」に対応するカラムから「rN」を削除
この表を用いて構文解析する際は、まずスタックトップの値と Act 列だけを見て、動作を決めます。 入力記号を読むことなく s あるいは rN を決定できます。
Act = s の場合、ここで初めて入力記号を 1 つ読み取ります。
スタックトップの値と入力した記号に対応する列を見て、sN の N を決定します。
例えば、スタックトップが 3 で入力が ( であれば N=3 となります。
N が決定したら、N をスタックにプッシュします。
LR(0) と先読み
表 3.22 を用いて解析する場合は先読みが必要に思えますが、変更した表では先読みせずに構文解析が可能であることが分かりました。
当然ですが、表の変更は、それぞれの行に含まれる動作が s か r のどちらかだけである場合に可能です。 言い換えれば、それぞれの行の中に s と r が混在しない文法は LR(0) に含まれ、そうではない文法は LR(0) ではない、ということになります。
表 3.19 を見ると、例えば状態 11 の行に r2 と s16 が混在しており、LR(0) では扱えないことが分かります。